Overview
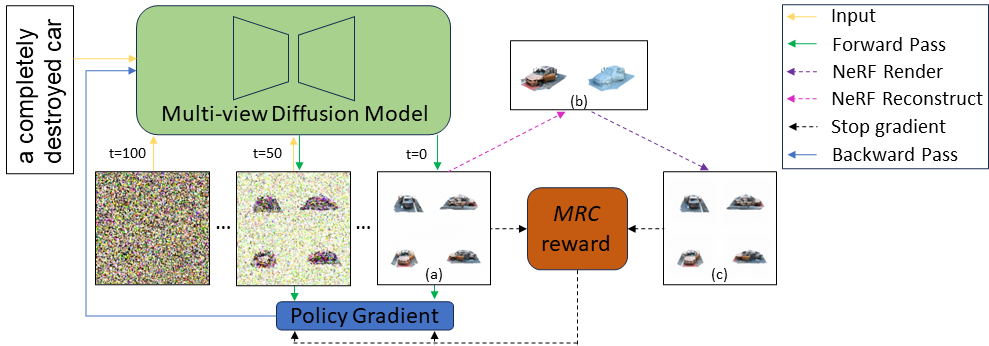
Figure 2. Overview of Carve3D. Given a prompt sampled from our curated prompt set and a initial noisy image, we iteratively denoise the image using the UNet. The final, clean image contains four multi-view images tiled in a 2-by-2 grid. MRC reward is computed by comparing (a) the generated multi-view images with (c) the corresponding multi-view images rendered at the same camera viewpoints from (b) the reconstructed NeRF. Then, we train the model with policy gradient loss function, where the loss is derived from the reward and log probabilities of the UNet’s predictions, accumulated over all denoising timesteps. By using only a set of training text prompts, our RLFT algorithm finetunes the diffusion model by evaluating its own generated outputs, without relying on ground truth multi-view images.

