Motivation
Current frontier video diffusion models can only generate short video clips (e.g. 10 seconds or 240 frames) due to the expensive O(N^2) long sequence modeling in DiTs. To enable long video generation, autoregressively applying video diffusion models is the straightforward solution.
How to generate longer videos?
- Increasing video length at inference time results in poor video quality.
- Naïve autoregressively video extension leads to drifting after 3-4 times.
A new way to noise/denoise?
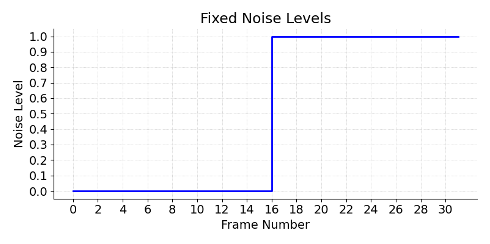
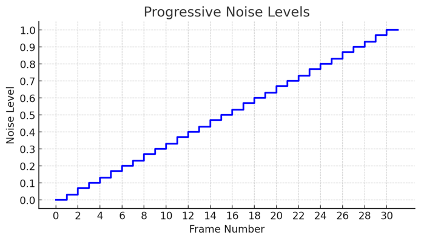
Instead of shared noise level among frames, assign progressively increasing noise levels to each frame!
Method
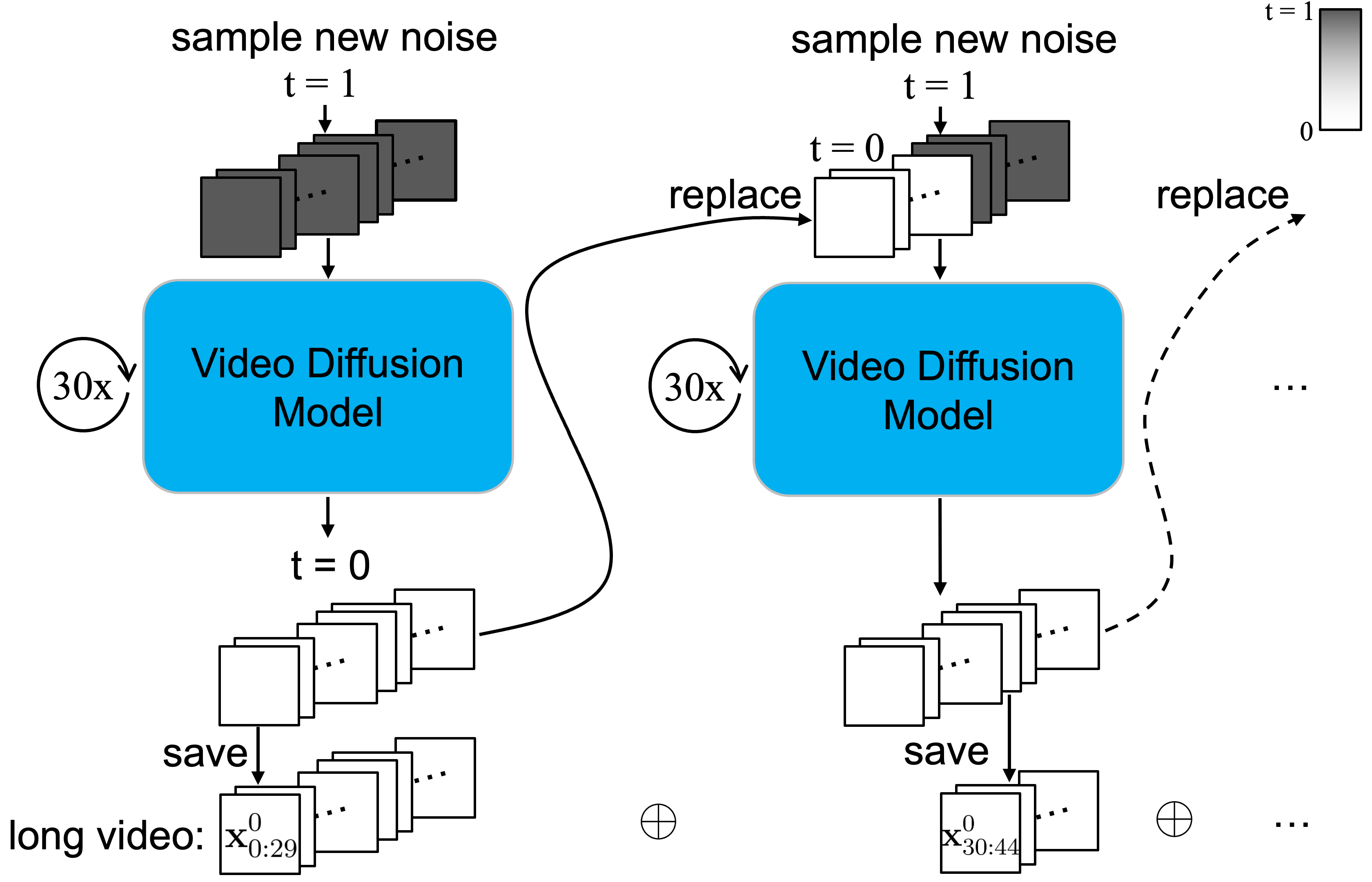
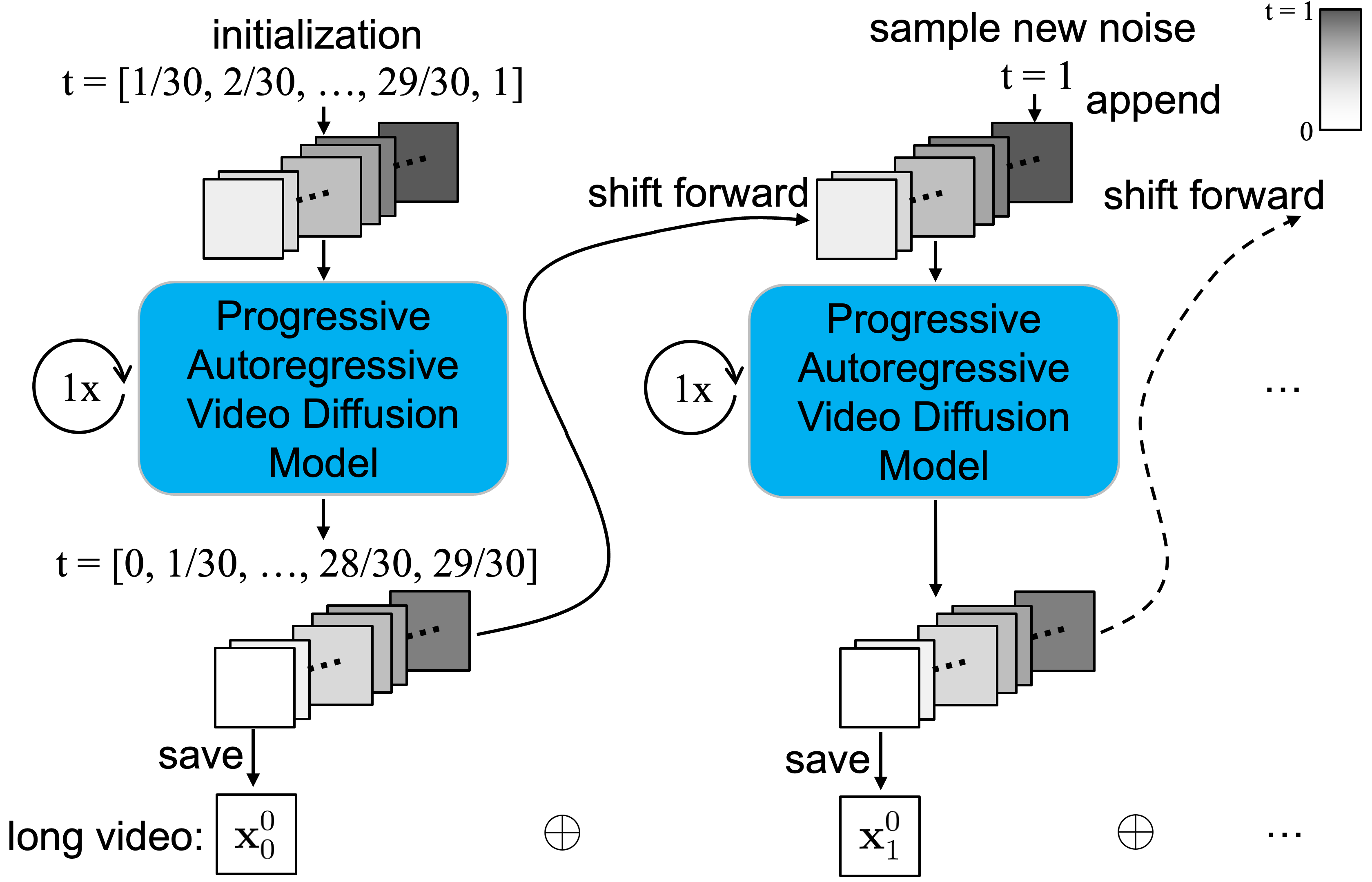
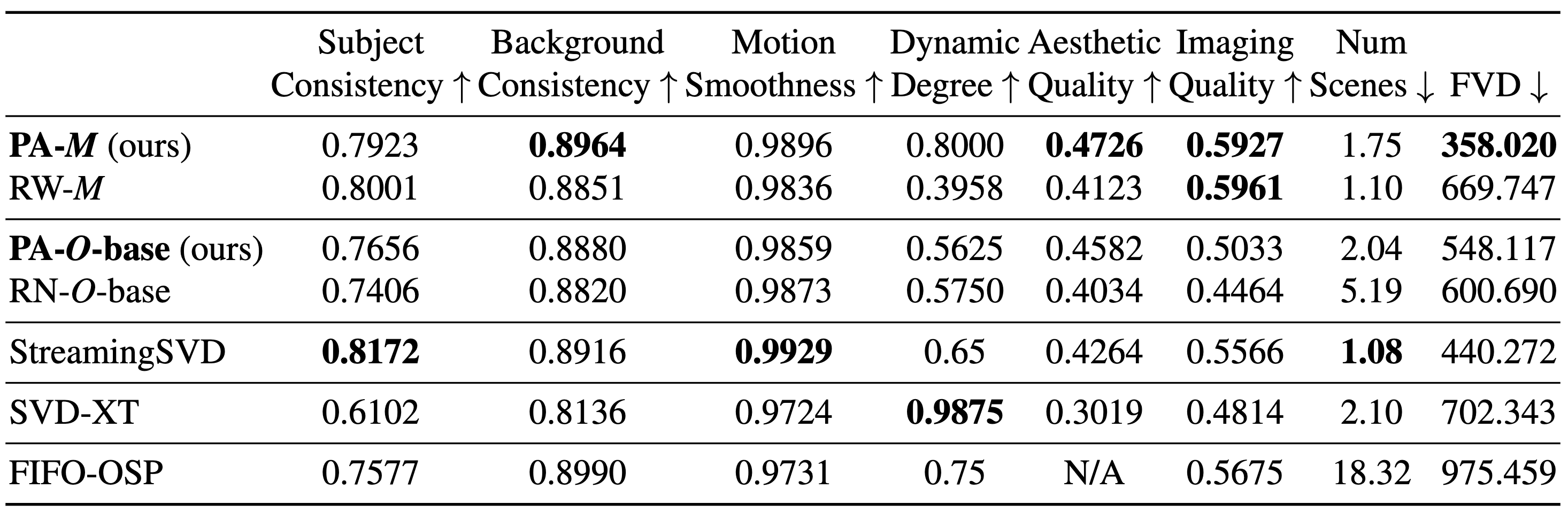
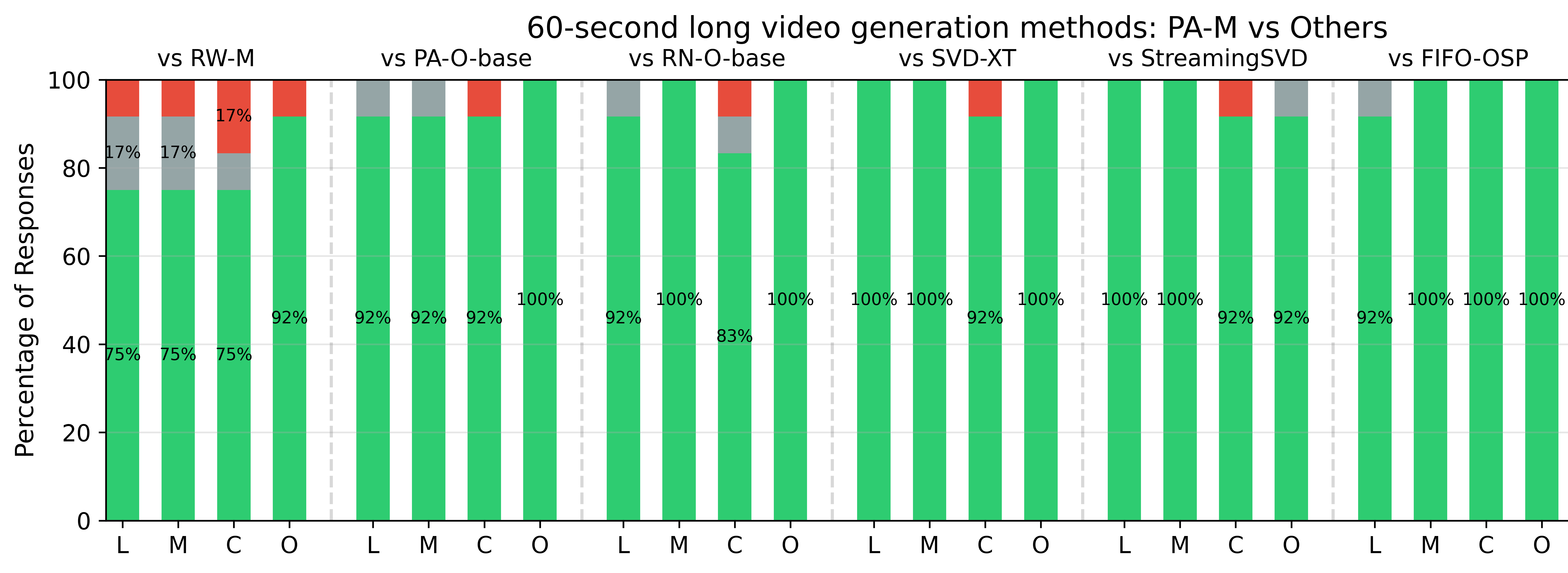
The replacement methods (left) vs. out PA-VDM (right).
Given previously generated F=30 frames,
Traditional replacement methods:
- Directly place condition frames at the beginning of noisy frames.
- repeat every 30 denoising steps.
- 😔 Severe drifting at 20s, small overlap, unnatural, limited motion.
- Assign per-frame, progressively increasing noise levels.
- Shift the frames by 1 and repeat every 1 denoising step.
- 😁 minimal drifting up to 60s, maximum overlap, natural motion. Better information propagation from earlier clean frames to later uncertain frames.